Uticaj Google efekta na performanse
Rezultati ovog istraživanja postali su šire poznati kao „Google efekat“. Njegov uticaj bio je u tome što je uspostavio vreme odziva veb-stranice od približno 200 milisekundi kao merilo za optimalno vreme odziva stranice. Takođe su ustanovili numeričke formule za određivanje negativnog uticaja sporijih performansi.Tehnologija je od tada značajno napredovala, posebno sa cloud i mikroservisnim tehnologijama, ali su osnovni principi performansi, otpornosti i dostupnosti ostali isti. Performanse, otpornost i dostupnost ključni su za stabilnost i efikasnost cloud-a u okviru preduzeća.Izvor: Google Research
Na konferenciji AWS:reInvent mogli smo da govorimo o tim faktorima objašnjavajući kako je Instana vodeća platforma za observability koja sprečava da problemi postanu ozbiljn
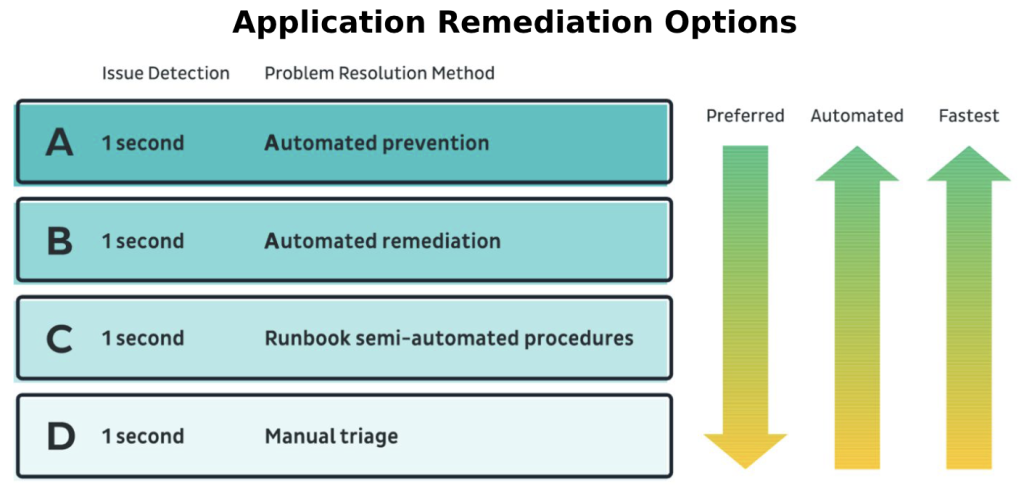
Opcije za otklanjanje problema u aplikacijama
Opcije navedene na slici „Application Remediation Options“ iznad određuju niz tipova otklanjanja problema — od potpuno automatizovanog upravljanja aplikacionim resursima (Application Resource Management — ARM), do poluautomatizovane i ručne popravke (MTTR). IBM Turbonomic ARM i AWS Compute and Cost Optimizer predstavljaju primere ARM alata za otklanjanje problema koji se takođe mogu koristiti za optimizaciju troškova cloud-a.Pošto je degradacija performansi novo vreme nedostupnosti, samo ručne metode popravke softvera nisu dovoljne za smanjenje degradacije. Samo observability u realnom vremenu u kombinaciji sa automatizovanim ARM-om može ne samo pomoći u otklanjanju degradacije, već i pomoći u sprečavanju da se problemi pretvore u incidente nedostupnosti.